|
Hi! I am a Research Scientist at Google DeepMind. I recently completed my PhD in Computer Science at Stanford University, advised by Prof. Chelsea Finn and affiliated with the Stanford Artificial Intelligence Laboratory (SAIL). During my PhD, I was supported by an NSF Graduate Research Fellowship and an OpenAI Superalignment Fellowship. I also spent six months as a full-time student researcher at Google DeepMind in London. Previously, in 2021, I received a joint B.S. in math and M.S. in computer science, both also at Stanford. I am originally from Boulder, Colorado, and outside of research, I enjoy spending time outdoors (hiking and backpacking), playing tennis, and learning to play the guitar. For three years I organized the Stanford CS Undergraduate Mentoring Program to help undergraduate students get involved with computer science research. My research focuses on developing principled methods for advancing the capabilities and reliability of intelligent agents in the physical world. I am excited by a broad range of machine learning topics, including reinforcement learning, data curation, test-time reasoning, robustness, out-of-distribution generalization, and embodied AI. In particular, I have been interested in how we can design self-improvement pipelines that leverage an agent's direct experience as information-rich probes of its weaknesses and opportunities for exploration. Some of my recent work has shown how we can harness experiential signals to push model performance through curating high-quality data [12], efficient exploration in reinforcement learning [14], and adaptive test-time reasoning at the timestep level and strategy level [10, 11]. This self-improving feedback-centric perspective has also informed my work on training and fine-tuning models to handle spurious correlations and generalize out-of-distribution [2, 5, 7, 8]. |

|
|
Please see my CV or Google Scholar for a full list of work. |
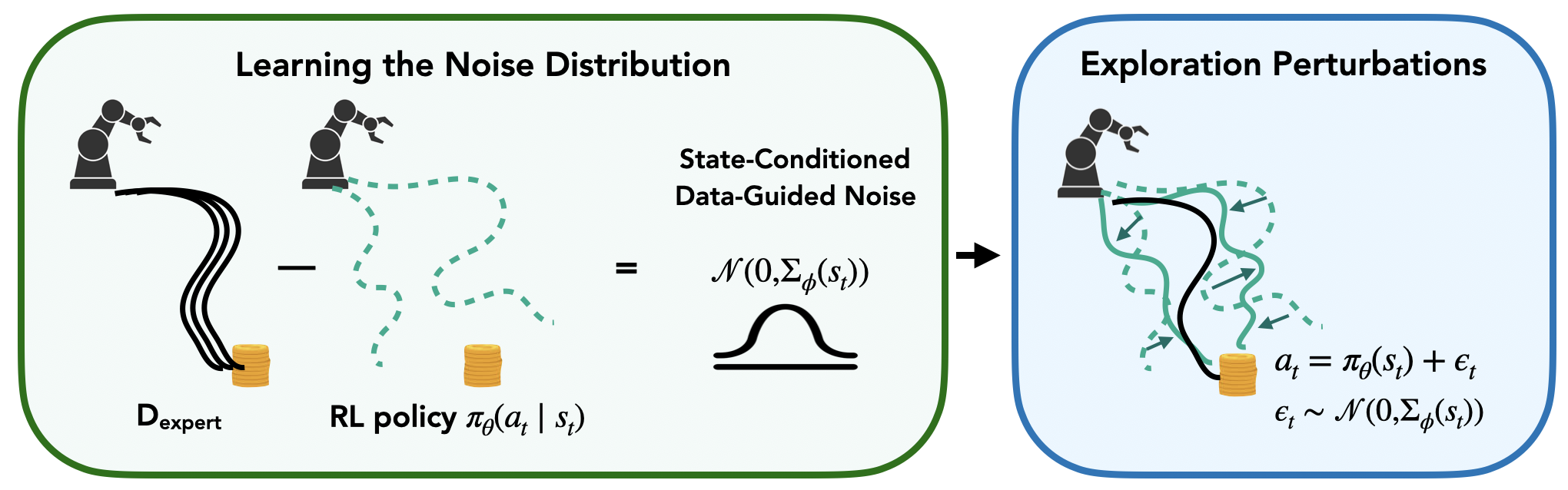
|
Perry Dong*, Alec M. Lessing*, Annie S. Chen*, Chelsea Finn Under submission, 2025 [PDF] We introduce Data-Guided Noise (DGN), a framework that uses expert data to shape exploration in order to improve sample efficiency for online reinforcement learning. |
|
|
Annie S. Chen, Philemon Brakel, Antonia Bronars, Annie Xie, Sandy Huang, Oliver Groth, Maria Bauza, Markus Wulfmeier, Nicolas Heess, Dushyant Rao. International Conference on Intelligent Robots and Systems (IROS), 2025 [PDF] We leverage the behavior of policy idling, where policies get stuck in a small region of states, to guide targeted exploration and iterative improvement via pause-induced perturbations. |

|
Annie S. Chen*, Alec M. Lessing*, Yuejiang Liu, Chelsea Finn Robotics: Science and Systems (RSS), 2025 [PDF] [Website] Data curation is crucial but is usually difficult and tedious. We introduce Demo-SCORE, an automatic way to curate, informed by online experience. |
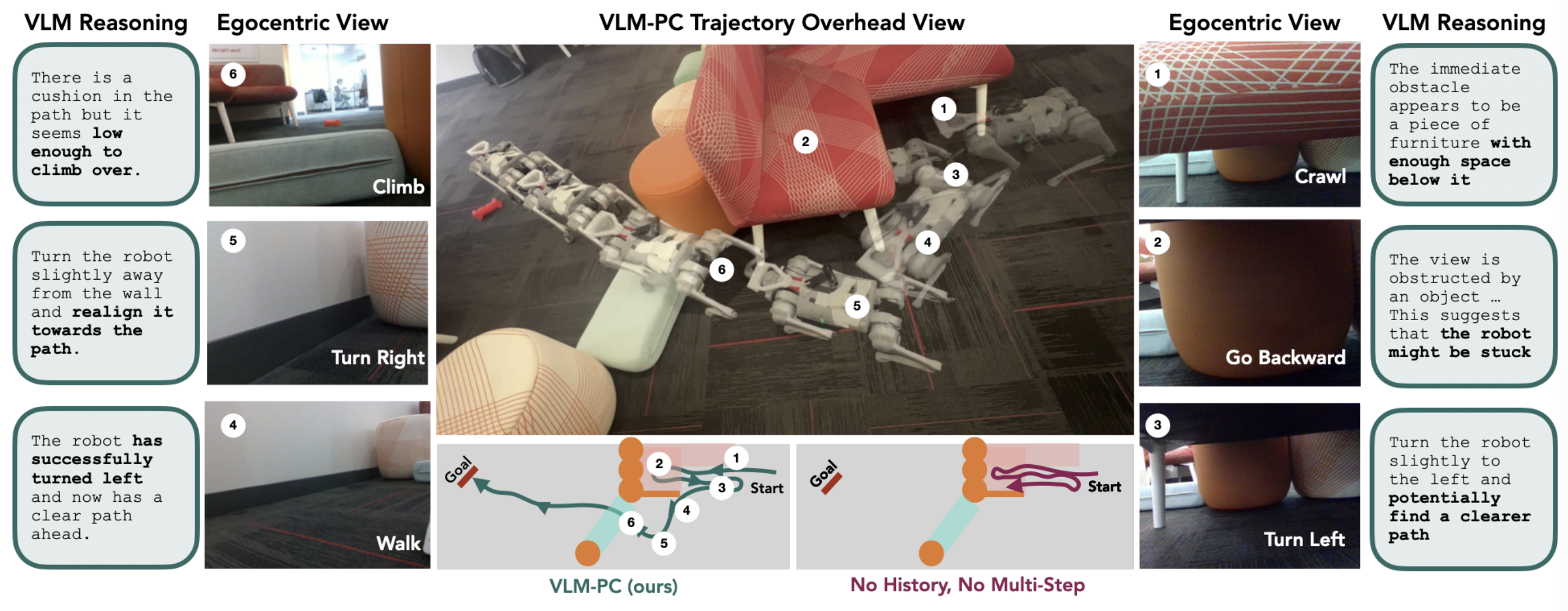
|
Annie S. Chen*, Alec M. Lessing*, Andy Tang*, Govind Chada*, Laura Smith, Sergey Levine, Chelsea Finn International Conference on Robotics and Automation (ICRA), 2025 [PDF] [Website] [Code] We propose VLM-PC to provide adaptive high-level planning, so that robots can get unstuck by exploring multiple strategies. |
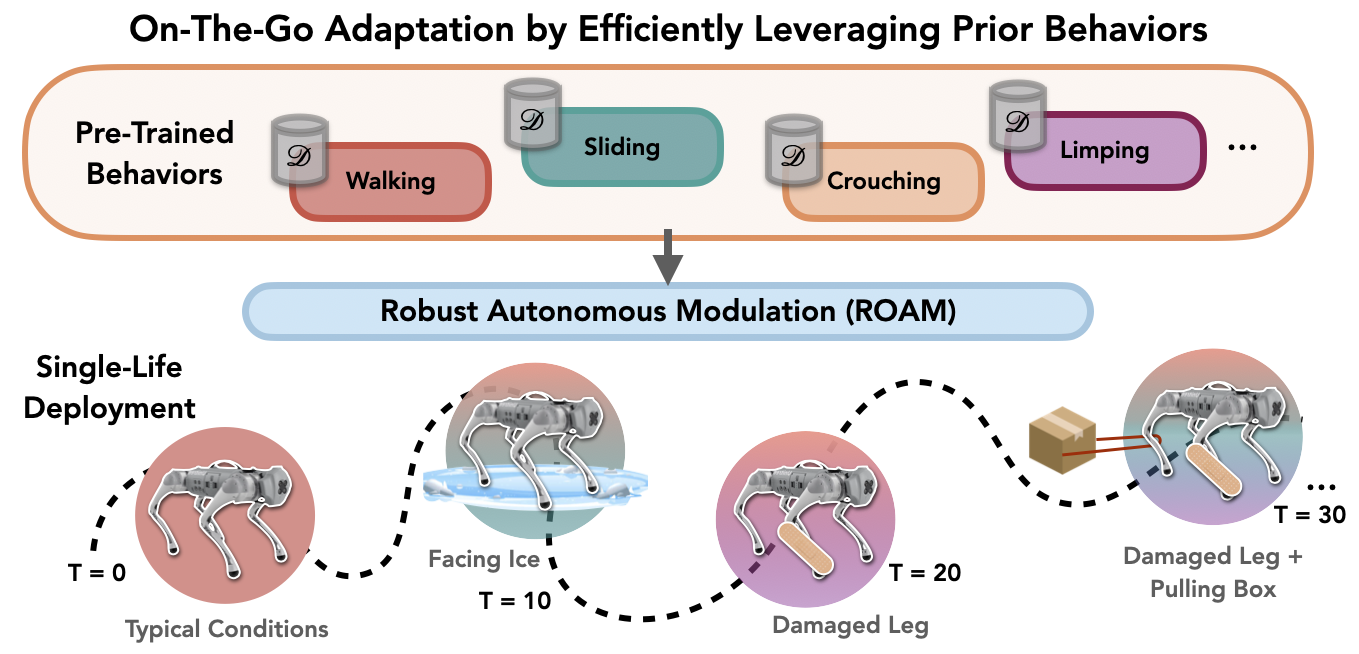
|
Annie S. Chen*, Govind Chada*, Laura Smith, Archit Sharma, Zipeng Fu, Sergey Levine, Chelsea Finn Conference on Lifelong Learning Agents (CoLLAs), 2025 [PDF] [Website] [Code] We propose Robust Autonomous Modulation (ROAM), a framework for efficiently leveraging pre-trained behaviors to adapt at each timestep to changing situations at deployment time. |

|
Johnathan Xie*, Annie S. Chen*, Yoonho Lee, Eric Mitchell, Chelsea Finn EMNLP, 2024 [PDF] [Code] RLHF often degrades the calibration of pre-trained LLMs. We propose a lightweight post-hoc calibration method, Adaptive Temperature Scaling (ATS), which addresses post-RLHF calibration degradation while maintaining performance improvements. |
|
Annie S. Chen, Yoonho Lee, Amrith Setlur, Sergey Levine, Chelsea Finn NeurIPS DistShift Workshop, 2023 [PDF] We propose COSMOS, a method that adaptively selects models with different strengths to perform well on both majority and minority subpopulations without needing target labels or group annotations. |
|
Annie S. Chen*, Yoonho Lee*, Amrith Setlur, Sergey Levine, Chelsea Finn International Conference on Learning Representations (ICLR), 2024 (Spotlight (top 5%)) [PDF] We propose Project and Probe (Pro^2), a lightweight + data-efficient approach for domain adaptation by learning diverse features. |
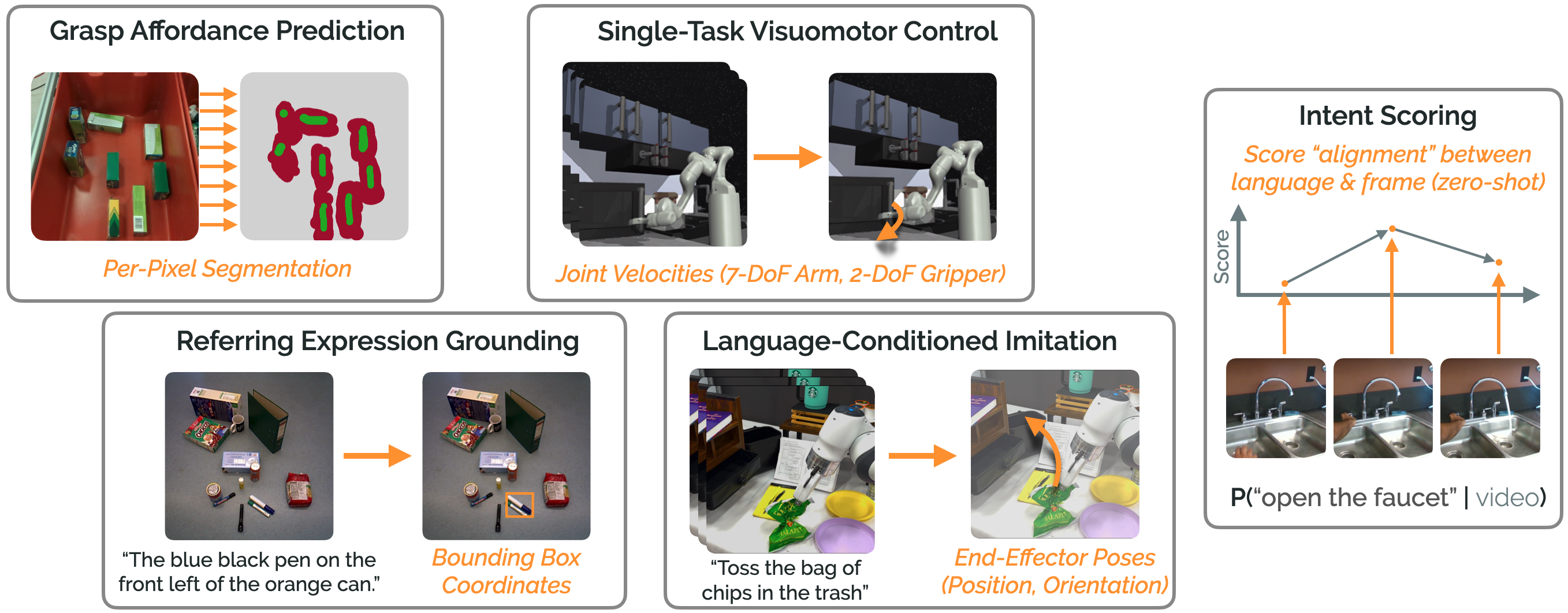
|
Siddharth Karamcheti, Suraj Nair, Annie S. Chen, Thomas Kollar, Chelsea Finn, Dorsa Sadigh, Percy Liang Robotics: Science and Systems (RSS), 2023 (Best Paper Finalist) [PDF] [Website] [Code] We propose Voltron, which uses language to learn better visual representations for a diverse range of robotics problems by trading off conditioning and generation. |

|
Yoonho Lee*, Annie S. Chen*, Fahim Tajwar, Ananya Kumar, Huaxiu Yao, Percy Liang, Chelsea Finn International Conference on Learning Representations (ICLR), 2023 [PDF] [Code] We show that selectively fine-tuning a subset of layers (surgical fine-tuning) outperforms fine-tuning all layers and reveals insights into the type of distribution shift present in the data. |
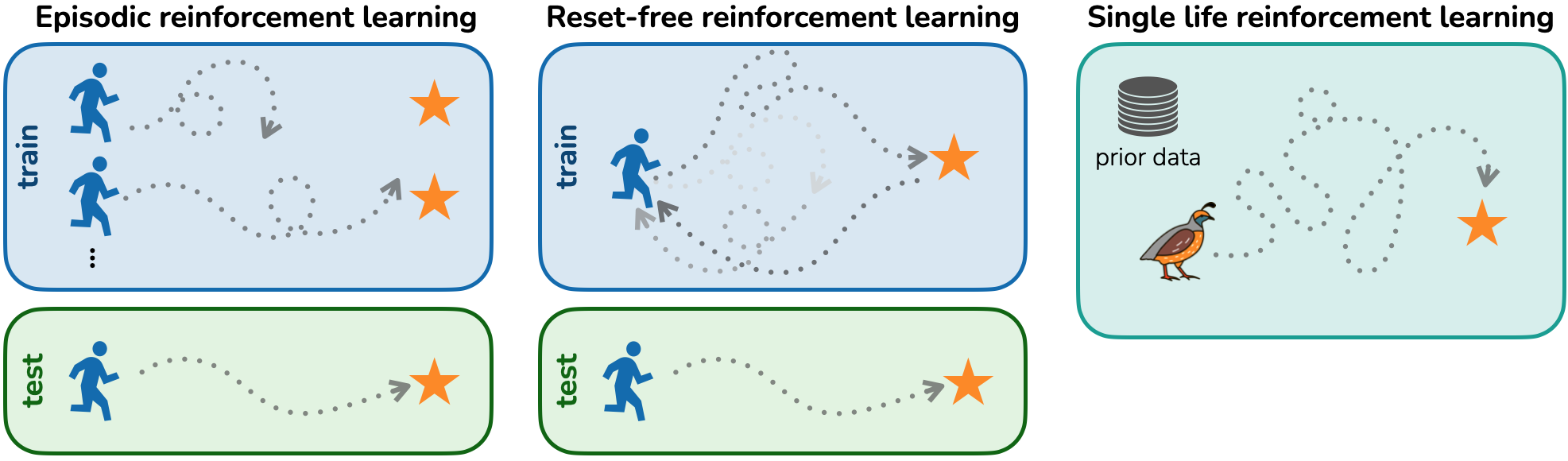
|
Annie S. Chen, Archit Sharma, Sergey Levine, Chelsea Finn Neural Information Processing Systems (NeurIPS), 2022 [PDF] [Code] We introduce Single-Life RL, where agents must adapt to novel tasks in a single trial without supervision, and propose QWALE, to guide agents when out-of-distribution to recover to prior experience. |
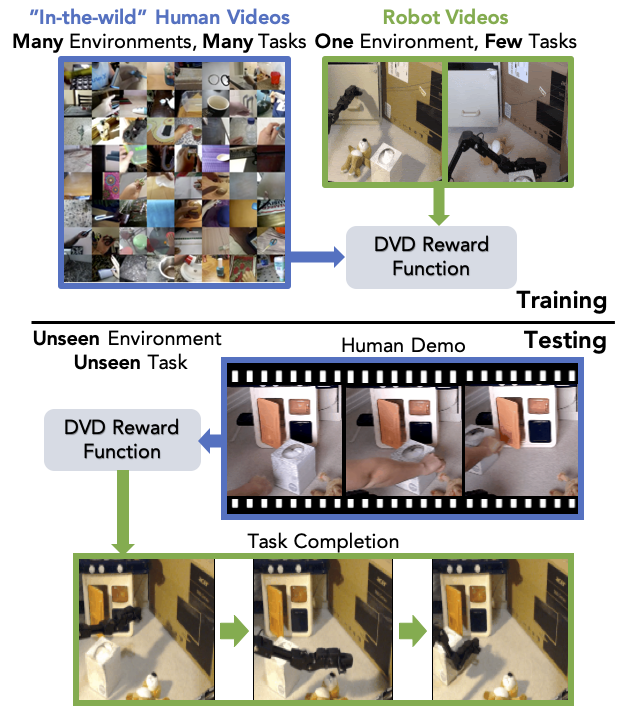
|
Annie S. Chen, Suraj Nair, Chelsea Finn Robotics Science and Systems (RSS), 2021 [PDF] [Website] [Code] We propose DVD: reward functions learned from in-the-wild human videos that generalize to new environments and tasks. |

|
Evan Z. Liu*, Behzad Haghgoo*, Annie S. Chen*, Aditi Raghunathan, Pang Wei Koh, Shiori Sagawa, Percy Liang, Chelsea Finn International Conference on Machine Learning (ICML), 2021 (Long Talk (top 3%)) [PDF] [Code] JTT improves worst-group performance without needing group labels by extracting and upsampling difficult, informative examples. |

|
Annie S. Chen*, Hyunji Nam*, Suraj Nair*, Chelsea Finn Robotics and Automation Letters (RA-L), 2021 [PDF] [Website] [Code] BEE uses weak human supervision to guide better robotic exploration for scalable data collection, enabling better offline RL. |
|
Website template from here. |